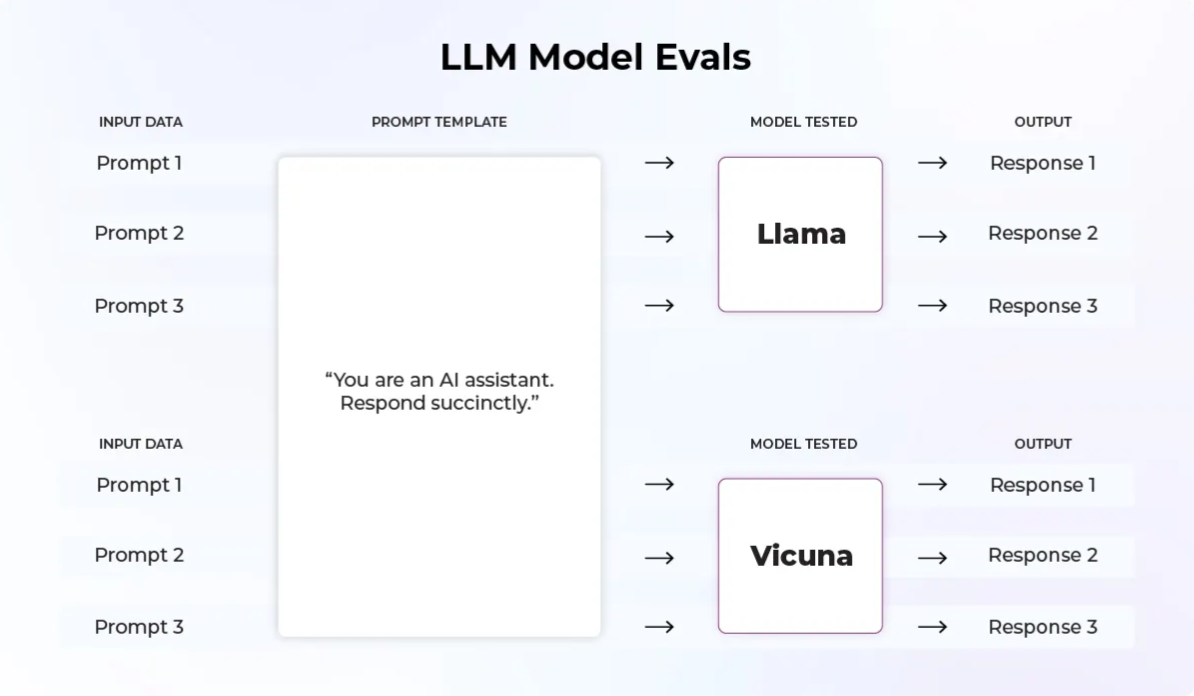
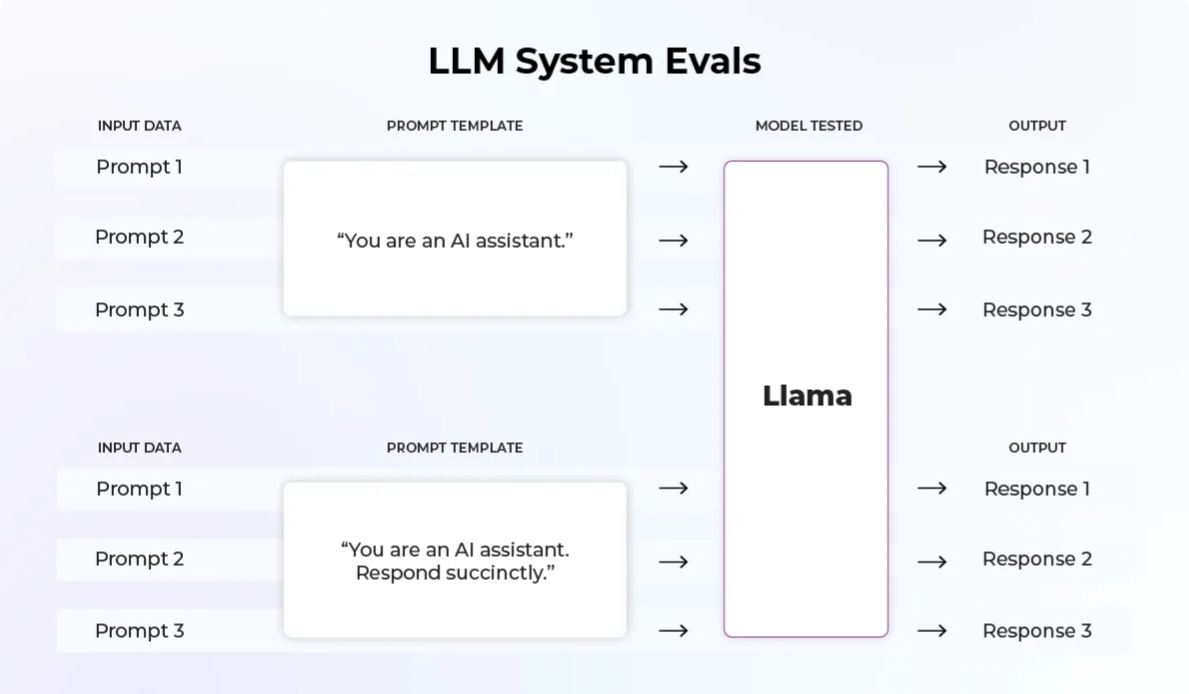
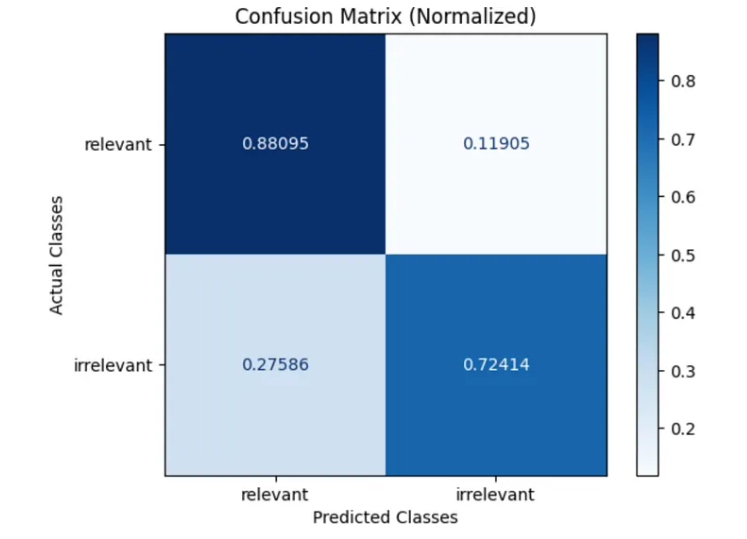
To properly evaluate an AI agent, you need to understand its main components:
Router: Think of this as the "boss" of the agent. Its job is to decide what the agent should do next and which "skill" to call based on what the user asks.
- Example: In an online shopping agent, if you ask about returns or discounts, the router decides whether to direct you to customer service, product suggestions, or discount information.
- Evaluation: The most important thing to evaluate here is whether the router called the right skill with the right parameters. If it picks the wrong skill (e.g., sending you to customer service when you asked for leggings), the whole experience can go wrong. You need to assess the router's "control flow" to ensure it's making the correct choices.
Skills: These are the actual "logical chains" that do the work. A skill might involve calling an LLM, making an API call, or both.
- Evaluation: Evaluating skills can be complex because they have many parts. For example, in a "Retrieval Augmented Generation" (RAG) skill, you need to check:
- The relevance of the information ("chunks") that were retrieved.
- The correctness of the final answer that was generated.
- A particularly tricky evaluation for skills is "path convergence". This looks at how reliably and efficiently (succinctly) the agent takes the right number of steps to complete a task. Different LLMs can lead to very different numbers of steps for the same job.
Memory: This part stores what the agent previously discussed and keeps track of the conversation's state.
- Importance: Since agent interactions usually involve multiple turns, memory is vital to ensure the agent doesn't "forget" what was said earlier.
An agent's operation can involve multiple router calls and skill executions, with memory keeping track of everything.
Every single step in an agent's journey is a place where something can go wrong. This is why you need to have
evaluations running throughout your application to help you figure out if an issue happened at the router level, the skill level, or somewhere else in the process.
For instance, at Arize, they have an agent (co-pilot) where they run evaluations at every single step of its operation. This includes checking the overall response, whether the router picked the correct path, if the right arguments were passed, and if the task was completed correctly.